
Aquí os traemos la segunda publicación de la traduserie para aprender localización web gratis en HTML utilizando software libre. Ya hemos aprendido las peculiaridades de la estructura de carpetas de un sitio web escrito en lenguaje HTML y, sobre todo, a diferenciar qué archivos son los importantes cuando nos enfrentamos a este tipo de proyectos.
Como ya vimos en esta primera entrega del tutorial de localización web gratis en HTML, solo tenemos un archivo con el que debemos trabajar (index.html), pues este se corresponde con la sección principal de la página, que será la que utilicemos para el ejemplo. No obstante, en un encargo de este tipo es normal que cada sección del sitio web se corresponda con un archivo HTML y que tengamos que traducir más de un archivo.
Los editores de texto para lenguajes de programación
Este tipo de programas tienen funciones básicas de edición de texto sin formato, similares a las del Bloc de Notas, con el añadido de detectar cuándo se ha escrito en un lenguaje de programación. Así, la herramienta reconoce la sintaxis de dicho lenguaje y lo resalta, colorea, delimita y divide en bloques de un modo muy visual e intuitivo.
De entre todos los programas de este tipo, Notepad++ y Sublime Text destacan sobre el resto. Para el ejemplo que nos ocupa, vamos a trabajar con Notepad++. Sin embargo, te animamos a instalar los dos y familiarizarte con ellos.
El texto traducible de un HTML
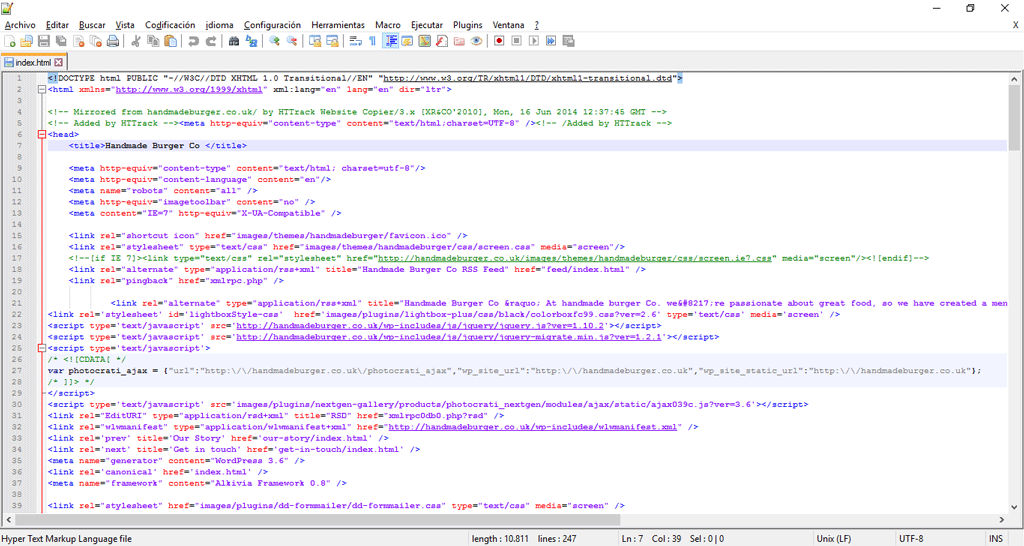
Una vez instalado, lo único que tenemos que hacer es abrir el archivo en HTML con uno de los dos programas. En nuestro caso, esto es lo que vemos cuando abrimos el archivo index.html con Notepad++:
 Haz clic para ver a tamaño completo
Haz clic para ver a tamaño completo
De esta imagen nos interesa fijarnos en la disposición de un archivo HTML cuando lo abrimos en Notepad++, especialmente la división en colores y etiquetas. En esta captura, solo tenemos como texto traducible el título de la página >Handmade Burger Co <, que por ser el nombre comercial de la marca no vamos a traducir. Sin embargo, vemos que el texto traducible siempre viene presentado en negro y delimitado por los signos «mayor que» y «menor que» de nuestro teclado en color azul. Por lo tanto, cuando trabajemos en localización web en HTML solo tenemos que ubicar los segmentos de texto con este formato y sustituirlos por sus equivalentes traducidos.
A continuación tenemos algunos ejemplos de capturas de otras cadenas de texto traducible:
 Haz clic para ver a tamaño completo
Haz clic para ver a tamaño completo
 Haz clic para ver a tamaño completo
Haz clic para ver a tamaño completo

De estas capturas podemos concluir que las etiquetas no se traducen y gran parte del archivo quedará en el lenguaje original, normalmente en inglés. Pero esto es algo que no debe preocuparnos, pues estamos hablando de elementos no visibles en la página. No obstante, existe un tipo de elementos traducibles que no vienen presentados en negro pero no podemos pasar por alto: los títulos. Si el título de la sección es Home, tendremos que cambiar tanto el texto traducible como el título en sí de la etiqueta Home en color azul que lo precede, pues sirve para mostrarlo en las pestañas del navegador y los títulos de página. Sin embargo, debemos mantener el vínculo que enlaza al archivo original en inglés para que no se rompa la relación de la estructura de los archivos y carpetas.
Asimismo, vemos que dentro del texto traducible hay etiquetas y símbolos de formato propios de HTML, estos incluyen las tildes, la ñ y algunos otros caracteres que necesitaremos a la hora de traducir. Haz clic aquí para consultar estos caracteres especiales.
Con todo esto podemos ver que la localización web en HTML no solo consiste en traducir el texto que veamos en negro. De hecho, en este archivo tenemos cierto texto en negro que equivale a etiquetas y no es parte del texto traducible. En cualquier caso, este es fácil de reconocer incluso sin un amplio conocimiento técnico.
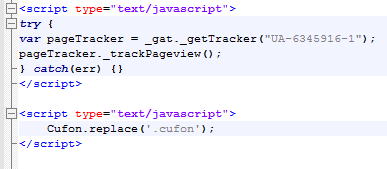
Aquí podemos ver texto negro NO traducible.
Ahora pasamos a traducir todo el archivo index.html —o archivos de la página en cuestión—. Una vez terminemos, solo tenemos que guardarlo y asegurarnos de que la estructura de carpetas sea igual a la original. Lo más importante de este paso es que los nombres de los archivos sean los mismos y su ubicación en la estructura de carpetas no haya cambiado.
En la próxima entrada veremos cómo localizar el último de los elementos que encontramos en una web HTML: las imágenes.
Para prepararte, puedes descargarte GIMP o Adobe Photoshop (en su versión de prueba). Y recuerda visitar el blog en los próximos días para enterarte de la tercera y última entrega de esta traduserie.
Si tienes alguna pregunta, déjanos un comentario para que resolvamos tus dudas.



