El uso de software libre es algo que debemos tener muy en cuenta en el día a día de una agencia de traducción, y en Intrawords no dudamos en compartir contigo algunos de nuestros métodos de trabajo con estos programas, para que tú también puedas beneficiarte de las herramientas gratuitas de mayor utilidad.
En esta entrada, vamos a profundizar en los tres editores de subtítulos gratuitos que creemos imprescindibles para conseguir resultados profesionales en nuestros encargos. De hecho, no sería exagerado afirmar que el tándem compuesto por Aegisub (también para MAC), VisualSubSync y Subtitle Edit conforma una suerte de suite de subtitulado realmente potente que nos hará la vida más fácil si sabemos cómo sacarles el máximo partido.
Lo más importante para entender la sinergia entre las tres herramientas es no concebirlas como editores de subtítulos independientes; sino aprovechar las tareas en que destacan cada una de ellas y crear un flujo de trabajo totalmente nuevo teniendo esto en cuenta. El eje central de esta forma de trabajar es Aegisub, que complementaremos con VSS y Subtitle Edit. Así, esta manera de trabajar podría resumirse en:
1. Aegisub: pautado, sincronización, traducción, edición y formateo de los subtítulos;
2. VisualSubSync: control de calidad y búsqueda de errores (QA);
3. Subtitle Edit: conversión de formatos de subtitulación.
1. Aegisub
Enlace de descarga de Aegisub
Aegisub es el único editor de subtítulos gratuito que permite temporizar los tiempos de entrada y salida con precisión de 1 cuadro —unidad mínima de medida de cualquier imagen en movimiento—. Esto es de gran utilidad para aquellos que quieran generar subtítulos con calidad profesional; de este modo, podemos ajustar los tiempos de los subtítulos para que coincidan con la entrada o salida de rótulos, textos en pantalla o cambios de plano, algo crucial para la calidad final del producto.
 Utiliza Ctrl+4 o Ctrl+6 (teclado numérico) para desplazar el cursor de posición
Utiliza Ctrl+4 o Ctrl+6 (teclado numérico) para desplazar el cursor de posición
El editor de estilos de Aegisub
Si hay algo que sitúa a Aegisub sobre el resto de editores gratuitos, es su editor de estilos. Muchos clientes nos darán especificaciones muy concretas sobre el aspecto final de los subtítulos o, incluso, nos facilitarán la fuente que debemos usar. Si este es el caso, el editor de subtítulos de Aegisub tiene las funciones necesarias para poder personalizar la fuente tanto como lo requiera nuestro cliente.
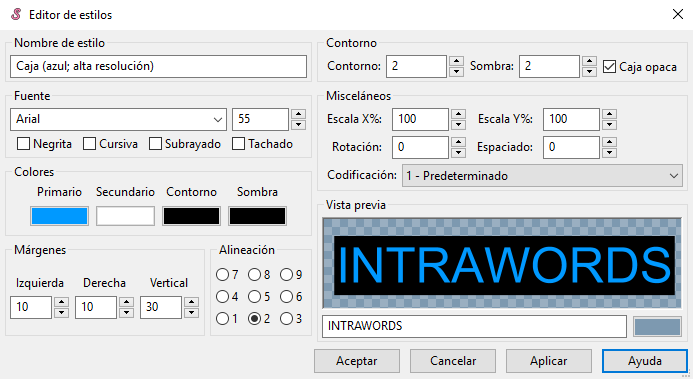 Podemos crear, nombrar y guardar diferentes estilos para usarlos en nuestros proyectos
Podemos crear, nombrar y guardar diferentes estilos para usarlos en nuestros proyectos
La posición en pantalla de los subtítulos
Otra de las funciones que más destaca de Aegisub, por ser el único editor gratuito que dispone de ella, es la edición de la posición en pantalla de los subtítulos. Algo estrictamente necesario si tenemos texto en pantalla (OST) coincidente con el audio que subtitular. Para modificar la posición en pantalla de los subtítulos, tan solo tenemos que introducir las etiquetas de posición de Aegisub: «{\aX}» —donde la «X» corresponde a la posición numérica del subtítulo en pantalla (del 1 al 9), empezando por la esquina inferior izquierda y llegando a la superior derecha—. Si buscamos una precisión mayor o el subtítulo aparece en un lugar poco habitual, podemos utilizar las coordenadas; es suficiente con seleccionar la línea de subtítulo que queramos mover y hacer doble clic en la posición en pantalla que deseemos; el programa generará una etiqueta de posición de coordenadas dentro de la caja de texto que tendrá el siguiente formato: «{\pos(coordenadas X,coordenadas Y)}
2. VisualSubSync
Enlace de descarga de VisualSubSync
VSS es otro editor de subtítulos gratuito con varios puntos fuertes, como la visualización de la onda de audio, la posibilidad de personalizar los atajos de teclado o la opción de añadir un archivo de referencia de subtítulos en VO; lo que resulta en un entorno de pautado y traducción de subtítulos muy completo. Sin embargo, la función que incorpora VisualSubSync que más nos interesa es su herramienta de control de calidad —Error checking en el menú Edit—. Si sabemos aprovechar sus funciones al máximo, tendremos una forma efectiva de llevar a cabo el QA check, además de totalmente personalizable.
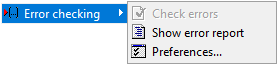
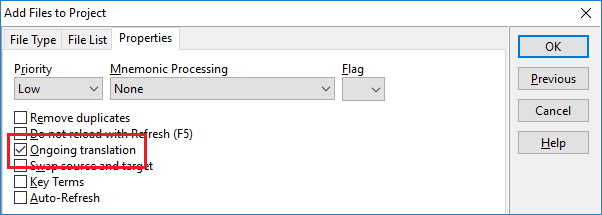
La opción Error checking
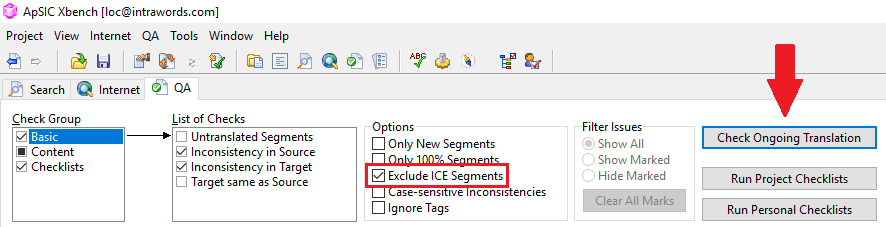
Como podemos ver en la imagen, a través de la opción Error checking podemos generar un informe de errores muy completo y, sobre todo, ajustarlo a medida si sabemos qué opciones cambiar. Accediendo a través de las preferencias del programa, nos concentraremos en la pestaña Subtitle y Error checking, que podemos ver en las siguientes imágenes:
 Opciones básicas pero imprescindibles en las que se basará el informe de errores
Opciones básicas pero imprescindibles en las que se basará el informe de errores
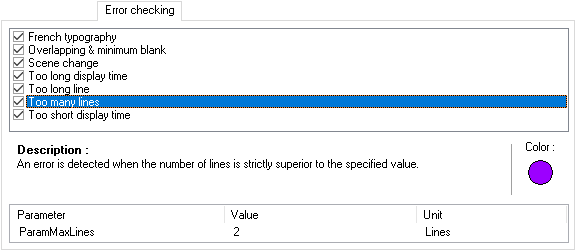 Opciones avanzadas que, mediante colores, nos advierten de posibles errores
Opciones avanzadas que, mediante colores, nos advierten de posibles errores
3. Subtitle Edit
Enlace de descarga de Subtitle Edit
El conversor que lo puede todo
Subtitle Edit es un programa de subtitulado que, por su interfaz tan poco intuitiva, suele pasar desapercibido al compararlo con Aegisub o VSS. Sin embargo, en Intrawords no le damos un uso convencional, sino que aprovechamos la innumerable lista de formatos con los que trabaja para hacer de esta herramienta un versátil conversor de formatos improvisado.
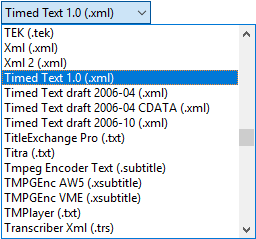
En la imagen de arriba, se muestran algunos de los muchos formatos a los que Subtitle Edit puede exportar subtítulos. Esto nos brinda infinitas posibilidades para satisfacer las necesidades del cliente y completar el encargo de una forma profesional.
Por ejemplo, si tenemos que crear unos subtítulos para Netflix, que suelen ser en formato Timed Text (XML), y en los que también, obviamente, habríamos de incluir el OST; la mejor opción sería utilizar Aegisub para pautar, sincronizar y modificar la posición en pantalla, guardar el archivo en un formato de Aegisub que soporte las posiciones en pantalla (ASS o SSA) y, a posteriori, abrir dicho archivo con Subtitle Edit para volver a guardarlo en formato Timed Text. De este modo, habremos generado unos subtítulos con calidad profesional y que cumplen los criterios de nuestro cliente.
Esperamos que hayas disfrutado conociendo más a fondo algunos métodos de trabajo de una agencia de traducción como Intrawords. Como podéis ver, a todos nos gusta el software libre, sobre todo cuando se trata de programas de tanta calidad.