
La traducción de páginas web es una de las vertientes más técnicas del ámbito traductor. Complicada desde el propio nombre, es necesario el término localización para reflejar la dimensión última de todo lo que implica la traducción de páginas web; ya que el proceso no solo se ocupa de la traducción de los textos, sino que también engloba la adaptación de elementos gráficos y culturales a un determinado contexto local —de ahí que hablemos de localización—.
Como expertos en traducción de páginas web, en Intrawords nos encanta sacar el máximo partido a las herramientas de software libre que pueden hacernos la vida más fácil como traductores. Ya hemos compartido algunas de estas anteriormente para hablar de subtitulación profesional, y hoy vamos a hacerlo para hablar de localización.
Así, te traemos la primera entrega de una serie de tutoriales para que aprendas a abordar la localización integral de páginas web en formato HTML. Es cierto que, en los últimos años, hay una preferencia por el lenguaje PHP. No obstante, los sitios web HTML han tenido un peso histórico muy importante. Por eso, a día de hoy, la red está poblada principalmente por páginas escritas en HTML; de hecho, muchos consideran necesario que los sitios web importantes estén escritos en HTML.
Algunas de las mejores páginas web escritas usando solo HTML
Tras esta pequeña reflexión sobre la importancia del HTML en la red tal y como la conocemos; vamos a empezar hablando de lo primero que debes conocer cuando te enfrentas a un encargo de traducción de una página web en HTML: su estructura de carpetas.
La estructura de carpetas de un sitio web HTML
A continuación, vemos una captura de pantalla de una estructura de carpetas típica de un sitio web programado en HTML. Esta se corresponde con la página que vamos a utilizar para los tutoriales de esta traduserie de localización de páginas web.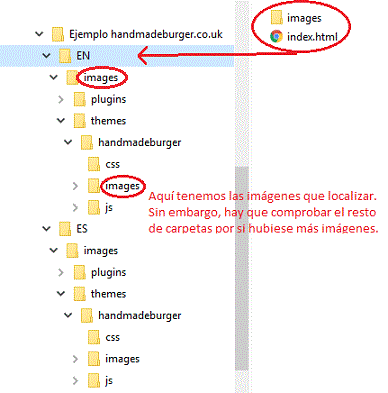
En este ejemplo vemos cómo, en muchas ocasiones, el lenguaje HTML no es precisamente intuitivo. Junto al archivo index tenemos una carpeta «images» que, en realidad, actúa a modo de carpeta raíz para el resto de archivos; tanto archivos de imagen como otros. Las que a nosotros nos importan están en la segunda carpeta «images». Como vemos, es muy importante explorar la estructura de carpetas al completo para no dejar de lado ningún archivo importante.
Esta estructura de carpetas puede variar sutilmente de unas páginas a otras; no obstante, este tipo de sitios web siempre se organizan en una suerte de árbol de carpetas vinculadas entre sí mediante enlaces internos que conectan los diferentes elementos.
Dentro de este «árbol» encontraremos archivos en numerosos formatos (HTML, JS, CSS, PHP y archivos de imagen como GIF o PNG). Lo más importante es saber con cuáles tenemos que trabajar y cuáles nunca modificaremos si no queremos dejar la página inservible. De este modo, los archivos que tenemos que tener controlados son los HTML y los de imagen, que suelen estar en formato PNG, GIF o JPEG.
Esto es muy útil para presupuestar encargos de localización, pues sabremos cuántas palabras hay que traducir en los HTML y cuántas fotos con texto tenemos que editar. Normalmente, en estos casos se utiliza un tarifado por palabras para los HTML y un precio fijo unitario para las imágenes. Por eso debemos tener en cuenta que algunas imágenes nos llevaran unos pocos minutos y otras podrán tenernos ocupados durante horas.
En este ejemplo, tenemos solo un archivo HTML para traducir, que se corresponde con la página principal o index. No obstante, es muy común encontrarse estructuras de páginas en HTML en las que cada archivo en dicho formato se corresponda con una sección del sitio.
En las próximas entregas de esta traduserie tutorial te explicaremos cómo localizar esos archivos HTML y cómo editar y traducir las imágenes con texto. Mientras tanto, puedes familiarizarte con este tipo de archivos descargándote cualquier sitio web seleccionando «Guardar página como…» o pulsando Ctrl+S en Google Chrome. Un buen profesional de la localización y traducción de paginas web tiene que entender el porqué de esta jerarquía de carpetas, los enlaces entre elementos y los archivos con los que se trabaja.
Te animamos a descargar Notepad++ y Sublime Text, dos programas gratuitos que utilizaremos en las próximas entregas y con los que podemos diferenciar fácilmente el texto que debemos traducir en un sitio HTML.
Si tienes alguna pregunta, déjanos un comentario para que resolvamos tus dudas.
¡Nos vemos en la próxima entrada de la traduserie, en la que seguiremos con la traducción de páginas web!



